

Paladin: SOTA Context Grounding Models
Every product team shipping AI features face the same risks: if your model’s claims aren’t backed by evidence, your applications isn’t reliable. Ungrounded outputs can mislead users, damage credibility and incur financial or operational costs. Grounding is the process of verifying that every claim has a clear basis in source documents (system prompt, RAG data, tool output, etc.).
By detecting unsupported statements in real time, Paladin enables developers to build agents, RAG systems and AI features with highest accuracy and reliability standards.
Paladin-Mini is a 3.8B parameter, open weight grounding model, can be found on Hugging Face, that labels every output as grounded or ungrounded based on a given input context. Built on Microsoft’s Phi-4-mini-instruct and fine tuned with specialized synthetic data, Paladin-mini delivers enterprise grade AI grounding with unmatched speed and accuracy, ensuring you deploy verified content.
The Paladin Models
Our State of the art (SOTA) models, Paladin-Large and Paladin-Mini, were purposely built to detect unsupported statements in real time. These models were trained with synthetic data, carefully generated from real usage patterns and three context grounding weak points that are everywhere.
Temporal Grounding
Temporal grounding are mistakes which occur when information related to time, like date ranges or operating hours, is misunderstood.

Mathematical Grounding
Mathematical grounding are mistakes which occur when a miscalculation leads to an incorrect conclusion. This is critical for anything involving pricing, discounts or numerical computations.
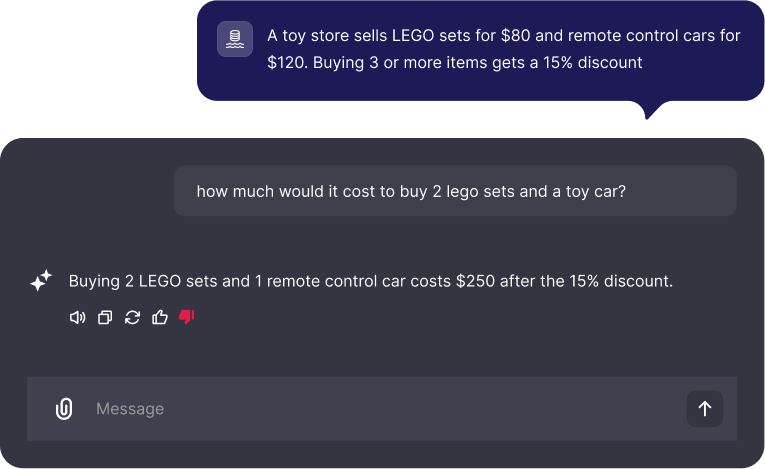
Logical Grounding
Logical grounding focus on the “chain of inference” if you can logically infer the claim from the doc it is considered grounded.

General Grounding
General grounding are mistakes which occur when AI output is unsupported by the provided context for any reason.
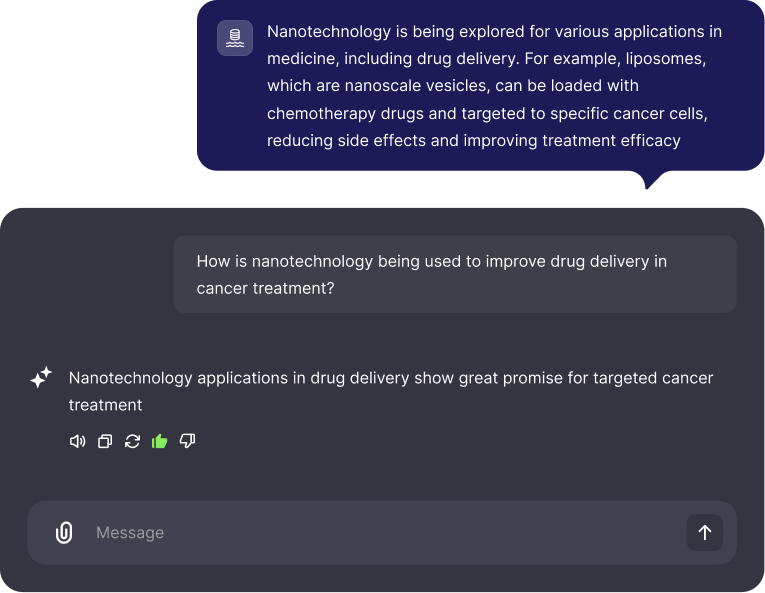
Why Paladin-mini Stands Out
Paladin-mini's effectiveness stems from several key factors:
- Compact & Efficient: With only 3.8 billion parameters it's ideal for environments with memory and compute constraints.
- Specialized Training: Its unique training corpus, combining public and synthetically generated data, directly targets complex real-world errors.
- Claim Level Operation: Focuses on detailed, claim-by-claim verification for enhanced accuracy and explainability.
Open model: Built on Microsoft's Phi-4-mini-instruct, promoting transparency and collaborative development, can be found on Hugging Face.
Grounding-Benchmark Dataset
Our grounding-benchmark dataset comprises 2,700 carefully curated document-claim pairs that span the full spectrum of grounding challenges. At its core, this dataset captures four intertwined reasoning dimensions. First, general entailment tests probe the model’s ability to recognize abstract semantic relationships, such as when a passage describes a trend or relationship indirectly.
Embedded within these pairs are multi-step arithmetic problems, inspired by real-world finance and e-commerce scenarios, which measure the classifier’s capacity for accurate numerical reasoning. Finally temporal parsing exercises require precise handling of dates and events, reflecting use cases in scheduling, historical research and compliance audits. By uniting these diverse tasks in a single benchmark, grounding-benchmark offers an industry-leading standard for assessing any grounding models true real world readiness.
Performance benchmarks and results
On the broader academic fact-checking tasks represented by the LLM-AggreFact subsets, Paladin-Mini exhibits stronger performance, with an average BACC of 77.7%.
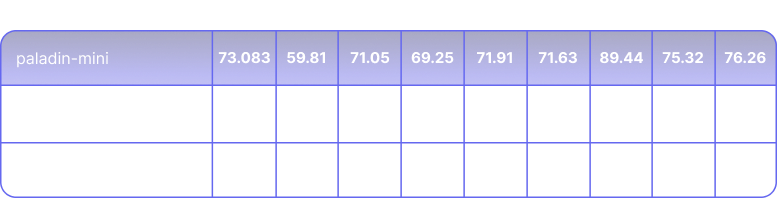
Paladin demonstrates exceptional accuracy, especially in logical and mathematical grounding, proving their reliability for real time applications.

The table below underscores Paladin-Mini unmatched efficiency for real time applications. It delivers excellent average accuracy (79.31% BACC) with 70ms latency.

Conclusion
Paladin-Mini sets a new standard for efficient, precise, open model grounding. By leveraging the grounding benchmark, developers can confidently deploy reliable, fact-based LLM outputs. Explore, contribute and ensure every AI assertion is rooted in evidence.
Paladin: SOTA Context Grounding Models




.png)